Navigating the Data Maze: Turn complex datasets into actionable insights

In healthcare and the life sciences, advances in DNA sequencing, omics, imaging, and clinical data capture are producing an unprecedented volume of multi-modal health data. However, navigating this vast data landscape can feel like a daunting maze, where the pace and complexity of data generation often exceed our ability to transform it into meaningful insights and interventions. This challenge is especially pronounced in biopharma, where breakthroughs depend on managing, accessing and converting complex datasets into actionable discoveries.
Biomedical research depends on a complex ecosystem of contributors. On one side are organizations that generate, curate, or steward high-value data—including precision medicine platforms, genomics consortia, and large-scale research programs. Research teams are on the other side, spanning biotech, pharma, and academic R&D, who require swift, dependable access to these data resources to identify novel biomarkers, refine clinical hypotheses, and speed the development of new therapies. Despite a shared mission of advancing biomedical science, siloed systems, cumbersome workflows and other factors often distance these groups.
Compliance obligations are another barrier. Data has become a strategic asset, but sharing it broadly with collaborators internally or externally can pose operational and governance challenges. For instance, governance and oversight become increasingly complex as collaborations expand, making it difficult to keep up with usage rules, data lineage, and audit trails. Scalability is also a challenge. Once researchers begin working with multiple partners — some in academia, others in commercial R&D — manual processes can quickly become bottlenecks, and ensuring consistency in compliance is difficult. Finally, sustainable operations demand a flexible, yet secure, governance approach that adapts to shifting data volumes, emerging user needs, and the possibility of monetizing curated datasets.
Biopharma breakthroughs depend on converting complex datasets into actionable insights.
Closing the gap between data generation and data usability
Research teams are trying to keep pace with fast-moving studies and clinical programs and can’t afford to be slowed by confusing data-use agreements or repetitious reformatting of files. The ability to quickly access multimodal data — from omics to imaging and sensor outputs — is imperative for timely advancements.
Researchers also need clarity on compliance, particularly with HIPAA, GDPR, and institutional policies. Given the collaborative nature of biopharma discovery, seamless, efficiency-driving tools for analysis and coding, e.g., R Analysis Environment, Python or Apache Spark plus the interactivity of JupyterLab, and sharing results are also essential. Overall, enabling researcher confidence that data is well-governed and standardized, allows greater focus on running experiments, validating findings, and advancing promising leads.
Connect and strengthen the biomedical research environment
Bridging the gap between biomedical data and research teams requires a shared framework for secure data ingestion, policy enforcement, discoverability, and integrated analytics. Through standardized data organization and distribution, data providers can lower overhead, while giving research teams quick, reliable access to necessary information. It also streamlines how updates or revised datasets are handled, mitigating the risk of confusion or duplication.
Typically, this approach is dependent on three main pillars.
- Automated policy enforcement enables usage rules to be set once, then applied consistently across all collaborations.
- Smooth data onboarding ensures that metadata, version control, and workflow-friendly formats let you incorporate new releases without manual chaos.
- Robust traceability provides a clear log of data access and analysis activities, giving both researchers and research teams data use visibility, and helping protect intellectual property.
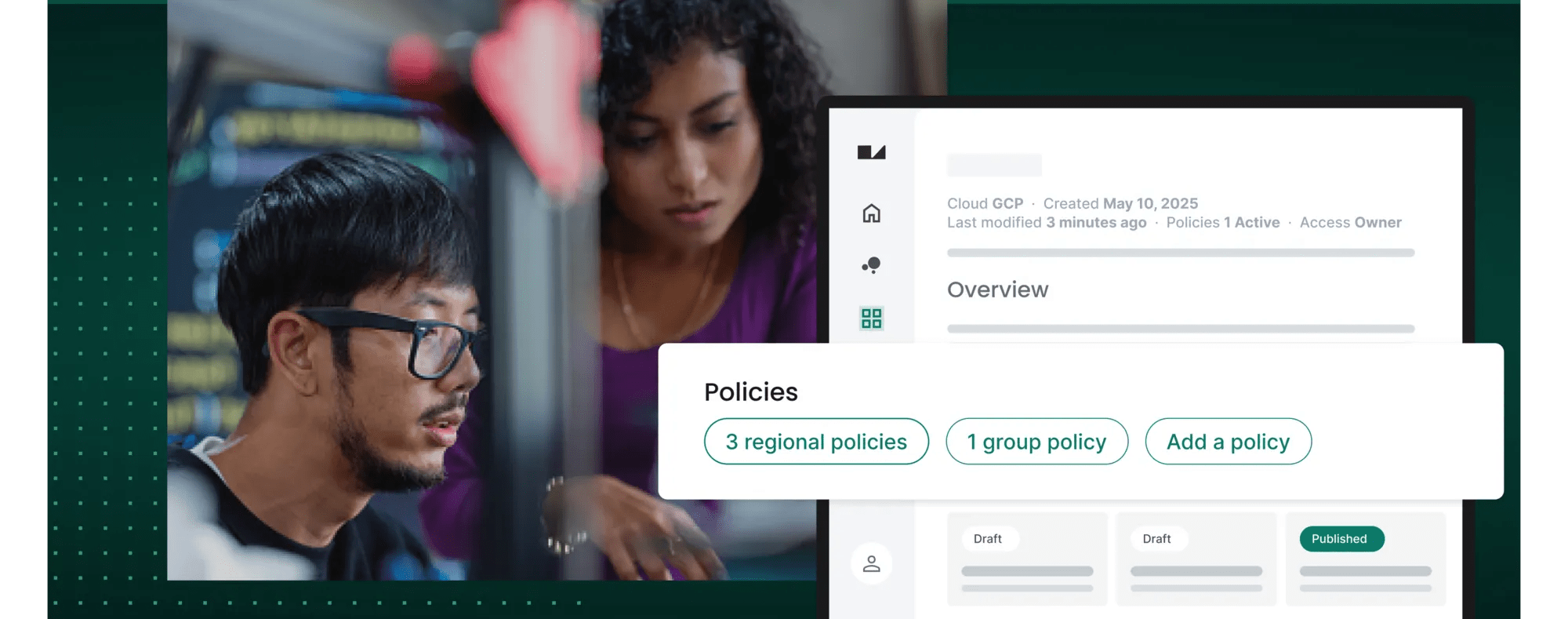
Realize the promise of your health data within an integrated analysis and governance framework with Verily Workbench.
Easier data governance, analytics and beyond
The National Institutes of Health (NIH) All Of Us Research Program, supported by the Researcher Workbench, an application developed in collaboration with Verily, is a good environment for example as it unifies clinical and genomic data from a large, diverse participant pool. By implementing standardized governance and robust analytics tools, it fosters parallel research among thousands of scientists, facilitating advances that might not happen in fragmented conditions. Instead, researchers can unlock the potential of large-scale data for catalyzing biomedical developments, instead of data acting as a barrier.
Dive deeper into strategies for overcoming these challenges in Verily’s whitepaper, Transforming Healthcare with Data. Access to learn how leveraging Verily Workbench enables:
- Structuring large datasets with consistent metadata
- Enforcing policy-driven compliance that allows data owners to preserve IP rights
- Integrating scalable analytics for data exploration without repeatedly retooling infrastructure
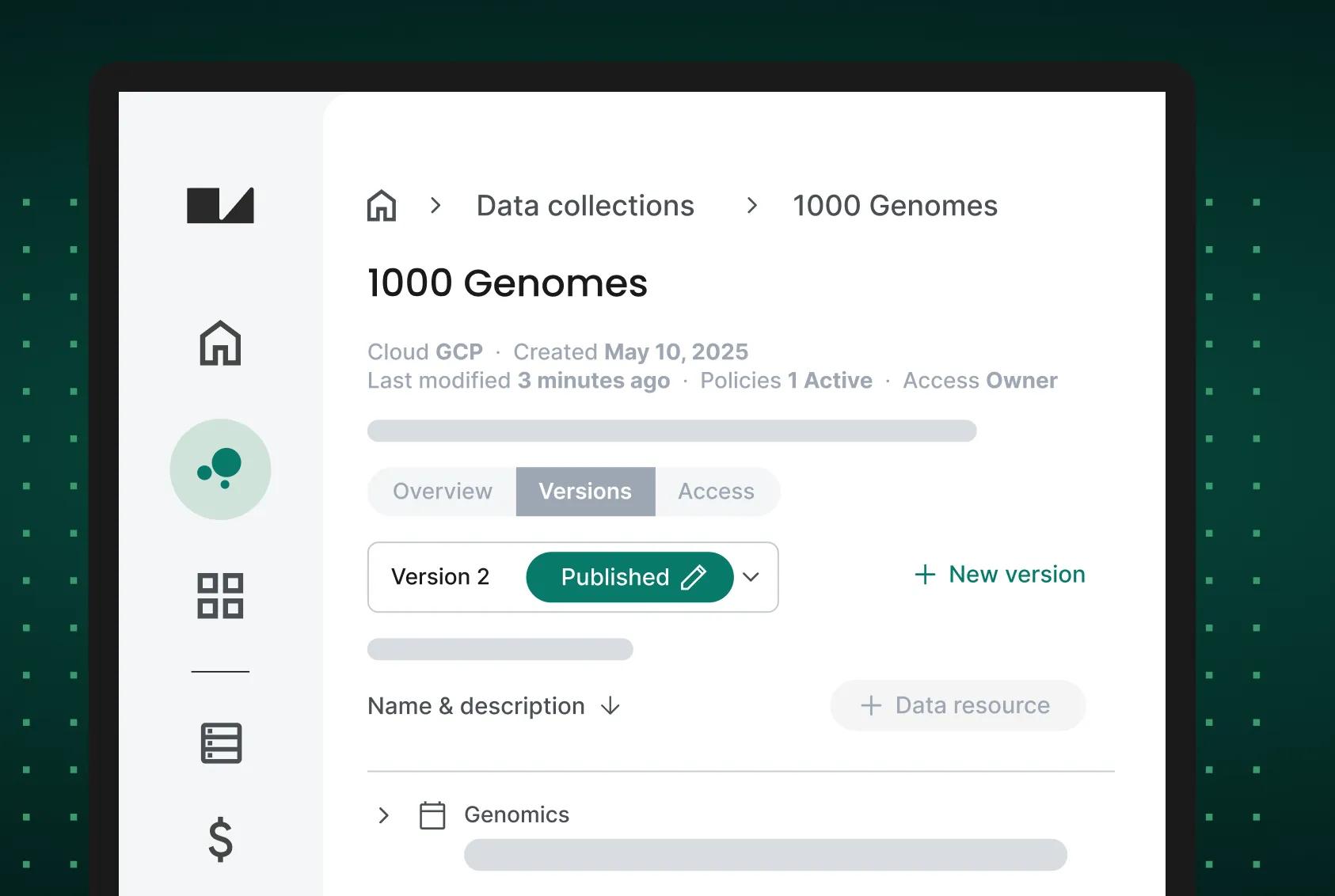
A workspace to transform healthcare with data
Verily Workbench, is powered by the Verily platform which securely organizes complex health data and provides the tools to enable users to safely and easily collaborate, analyze unified data sets and efficiently curate data to advance research and discovery. By unifying governance, access, and collaboration in a single environment, it allows data stewards to maintain control while giving researchers seamless, compliant access to curated datasets. This shared infrastructure reduces friction, increases reproducibility, and accelerates the journey from data to discovery.



