Elevating FHIR data quality: A multi-resource approach to comprehensive validation
FHIR® (Fast Healthcare Interoperability Resources) is the backbone of modern clinical data pipelines, standardizing data exchange across healthcare systems. A FHIR-native platform eliminates the need for translation into other languages like SQL, preventing unnecessary errors. When dealing with healthcare data, mistakes can have a cascading effect on the information connected to an individual. For instance, an inaccurate condition diagnosis can lead to incorrect prescription or any act based on data, directly jeopardizing patient care and outcomes, with a subsequent cascading affect on the entire data trail. What if safeguards caught these mistakes before they snowballed? This is the benefit of standardizing quality checks.
Our data quality strategy focuses on assessing data at its source — the FHIR level — rather than on transformed tabular formats. This is a key benefit for our healthcare and research partners, as it preserves the original data lineage and ensures complete traceability. By leveraging FHIR standard and FHIR-native languages like CQL, we reduce errors and empower clinical informatics teams. This shortens the feedback loop and ensures traceable data lineage. The Pre platform's ability to detect quality issues in near real-time is a key highlight, preventing the “snowball effect” of incorrect data.
Beyond basic checks: The inadequacy of single-resource FHIR validation
Adopting FHIR alone doesn’t ensure high-quality data — the real challenge often lies in the connections between resources. Verily has built the tools to support FHIR implementers and data engineers, giving them the context to support reliable solutions by moving beyond local standard validation.
Standard FHIR validation has a critical gap: it’s resource-local. FHIR provides a rigorously defined “lego set” of clinical resources, where each Observation or Procedure must satisfy its own rules for cardinality, data types, and value sets. However, the native validator stops at the edge of a single resource. It cannot detect contradictory stories told by linked resources, because, as HL7’s spec notes, the context of the subject is not inherited through references [6].
This gap creates severe, real-world data quality problems. Consider a stateful streaming pipeline designed to assemble complete patient records. First, it processes data for Patient/123, setting her as the “patient in context.” Moments later, a Condition arrives for a different patient, Patient/789, that references a prostate cancer. Due to a hypothetical bug in state management, the pipeline might fail to switch context to the new patient. It incorrectly associates this new Condition with the patient it still has in memory: Patient/123.
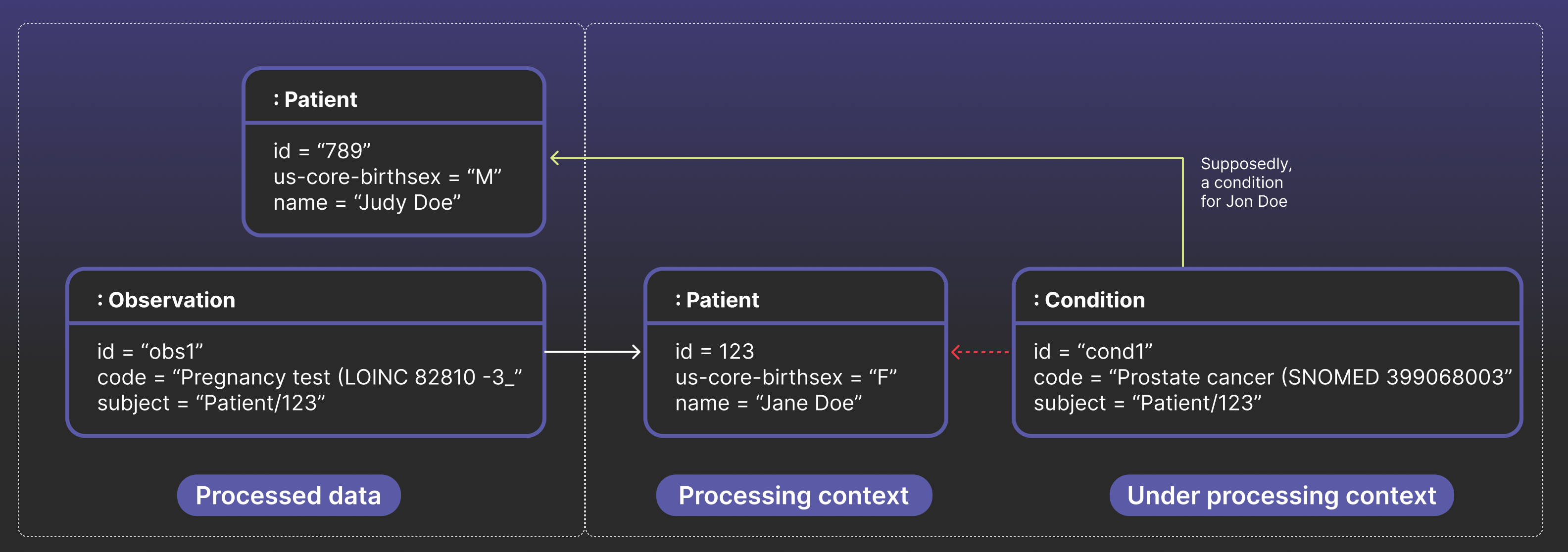
The result is a structurally valid, but most likely incorrect, record — a patient that was assigned female sex at birth now appears to have prostate cancer. Local checks on each resource would pass. These bad links then cascade downstream, triggering flawed analytics, rejected CMS submissions, and even leading to inappropriate treatment decisions. True data quality, therefore, requires us to move beyond asking, “Does each resource look valid?” to “Do the resources make sense together?”.
At Verily, FHIR events — Observations, Encounters, DiagnosticReports, Claims — stream in seconds. A streaming job groups related resources to validate cross-resource rules, like matching an Observation’s subject to the corresponding Patient or checking A1C values against demographics. Records that fail are quarantined for alerts; clean data flows to analytics and dashboards. By catching errors minutes after arrival, this approach implements data quality much earlier in the process while preserving FHIR interoperability, delivering trustworthy, actionable data to clinicians and reporting pipelines.
This post explores how native FHIR tools — FHIRPath and Clinical Quality Language (CQL) — can be used to validate these critical relationships, improve clinical trust, and avoid brittle, ETL-heavy alternatives.
Categorizing critical connections — understanding multi-resource validation rules
FHIR’s validator checks within a single resource — cardinality, data types, value sets — but many quality issues span across resources or populations. Depicted in the table below, we see three tiers of validation: binary rules (e.g., an Observation can’t precede a patient’s birth date), n-ary rules (e.g., a discharge Encounter must reference a valid summary authored by a licensed Practitioner), and population rules (e.g., 90% of participants completed a survey). Binary and n-ary checks can run in real time, while population rules close the loop at scale.
| Cardinality Type | One-Sentence Rule Example | Why It Matters |
|---|---|---|
| Binary(2 resources) | Observation.effective ≥ Patient.birthDate | Prevents impossible chronologies (labs recorded before birth) that break longitudinal analyses. |
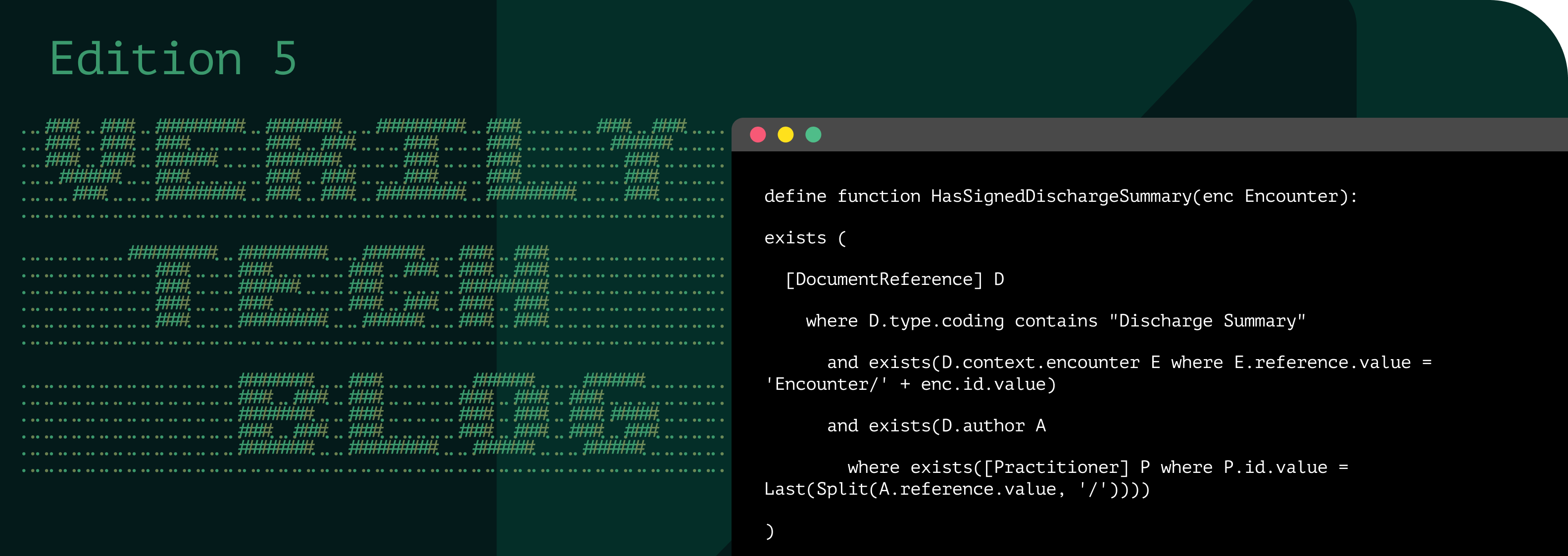
| N-ary(≥3 resources, same clinical event) | Finished Encounter → DocumentReference “Discharge Summary” → Author is active Practitioner | Guarantees every inpatient stay is closed with a signed discharge summary, essential for care continuity and billing audits. |
| Population(aggregate across many records) | “≥ 90 % of study participants completed Survey X” | Validates dataset completeness for research or CMS quality measures; gaps can invalidate results or payments. |
Why SQL falls short — even if it’s familiar
SQL is often used [4,5] for multi-resource FHIR validation, since its joins and aggregations easily confirm references across entities. When FHIR data is staged in warehouses like BigQuery or PostgreSQL, SQL can assert that every Observation links to a Patient or that a discharge note references the right encounter. But this comes at a cost: flattening FHIR’s hierarchy creates brittle ETL, terminology checks fall outside SQL’s strengths, and scripts become harder to maintain as rules grow. SQL works well for inter-entity checks, but relying on it alone risks long-term scalability and governance issues.
FHIR-native alternatives: FHIRPath and CQL
To avoid data reshaping and heavy ETL, validation can be performed directly within the FHIR model. This approach uses two interoperable, HL7-endorsed languages. FHIRPath offers a lightweight, XPath-style syntax ideal for single-resource or “single-hop” checks (e.g., Observation.subject.resolve().exists()). For more complex, cross-resource validation involving joins, temporal windows, or terminology, the more feature-rich CQL is used. Together, they create a powerful, FHIR-native rule set.
FHIRPath: Best for binary, stream-based checks
FHIRPath can reach across resources with two built-in operators — its “secret weapons” for cross-resource validation
resolve() follows a Reference, so a path that starts on one resource can hop to the target of that reference; memberOf() checks whether a code (or Coding/CodeableConcept) belongs to a given ValueSet. An implementation of both functions is available in the Verily FHIRPath evaluator [7]. Together they turn the single-resource language into a concise, stream-friendly validator for binary relationships. This validates resource connections to prevent misassociated and incorrect records.
For example:
Observation.effective >= subject.resolve().birthDate
reads: “the effective date of this Observation must be on or after the birth date of the Patient referenced in subject.” A terminology rule is equally compact:
Observation.code.memberOf('http://loinc.org/vs/HbA1c')
reads: “whether the Observation’s code corresponds to an HbA1c test.”
While FHIRPath expressions are declarative and side-effect-free, allowing them to run inline in a streaming pipeline with minimal overhead, their limitations emerge in more complex scenarios. For simple, binary constraints like date comparisons and single-hop reference checks, FHIRPath provides a highly interoperable first line of defense.
However, beyond a single resolve(), it struggles with fan-out joins, which become unreadable, and it offers little modularity or reuse. Crucially, it lacks aggregation operators, making it impractical for computing population-level metrics. For these richer scenarios, teams turn to CQL for advanced joins, temporal logic, and terminology, or to analytic engines like SQL and Beam for large-scale aggregates.
CQL: Best for N-ary and population-level checks
Clinical Quality Language (CQL) gives you a single, declarative syntax for rules that would otherwise sprawl across FHIRPath snippets and SQL joins. In one library you can state, “Every finished inpatient Encounter must include a DocumentReference of type 18842-5 whose author is a Practitioner with an active license,” and the engine enforces reference integrity, timing, and terminology in one pass. See below:
Built-in temporal operators express rolling or anchored windows without brittle date math — CalculateRollingAverage( Measure, 3 months ) reads exactly as it executes. Value-set functions (code in "Pregnancy SNOMED") resolve and subsume codes inside the engine, eliminating external joins. Cohort filters target compartments directly — Encounter E where E.subject in "Research Cohort" — so the same logic works for patient-, encounter-, or organization-scoped audits. Finally, CQL runs in two modes: in-memory for compartment level, or transpiled to SQL/Beam for warehouse-scale scans, giving teams one portable rule set from bedside checks to population analytics.
Unlike FHIRPath, CQL transforms data-quality rules into modular, maintainable assets: authors can define functions and libraries once, version them, and reuse them across projects. For example, IsDischargeSummarySigned() can be referenced by any rule, automatically inheriting fixes and updates. With CQL, organizations gain scalable, governed, and reliable data-quality logic instead of scattered, error-prone expressions.
FHIRPath and CQL are not competing — they are complementary tools that serve different needs in a FHIR-native validation strategy. FHIRPath is ideal for simple, inline checks on one or two resources, while CQL is leveraged for complex, reusable logic that spans multiple resources and cohorts. This approach to validation — rooted in versioned governance and committed to the FHIR ecosystem — guarantees interoperability and scalability. It effectively halts the “snowball effect” of incorrect data, empowering clinical informatics teams to maintain high data quality.
References
1. Codd, E. F. (1970). A relational model of data for large shared data banks. Communications of the ACM, 13(6), 377-387.
2. Kramer M. A. (2023). Reducing FHIR "Profiliferation": A Data-Driven Approach. AMIA 2022 Annual Symposium Proceedings, 634–643.
3. Shute, J., et al. (2024). SQL has problems. We can fix them: Pipe syntax in SQL. Proceedings of the VLDB Endowment, 17(12), 4051-4063.
4. Sync for Science "Qualifier" Repository. Available at: https://github.com/sync-for-science/qualifier
5. Google FHIR-DBT-Analytics Data Quality Models. Available at: https://github.com/google/fhir-dbt-analytics/tree/master/models/metrics/data_quality
6. HL7 FHIR R4 Specification: References. Available at: https://hl7.org/fhir/R4/references.html#2.3.0
7. FHIRPath. Available at: https://github.com/verily-src/fhirpath-go